Using the INTEG Common Library
Creating the Libraries
Code examples for the JNIOR use a library that makes creating applications far easier on the JNIOR. To get started first download the SDK file containing the libraries below.
| Name | Version | Release Date | Size | MD5 |
|---|---|---|---|---|
| Embedded JNIOR SDK | v1.0 | Nov 08 2019 | 1.6 MB | 75233695d8010ef8bea3a791c76d43be |
Once this file is downloaded, you’ll want to extract the files to a folder you create. Make sure you remember the file location, as we’ll be using it later. You can get it by right clicking the location bar at the top when in the file explorer.
Once you’ve extracted the SDK, you’ll then want to setup the library in your IDE. INTEG creates applications for the JNIOR through NetBeans, so how to setup the library will be explained in NetBeans. In NetBeans, you’ll want to create the library by going to Tools -> Libraries. This will open the Ant Library Manager Dialog Box.
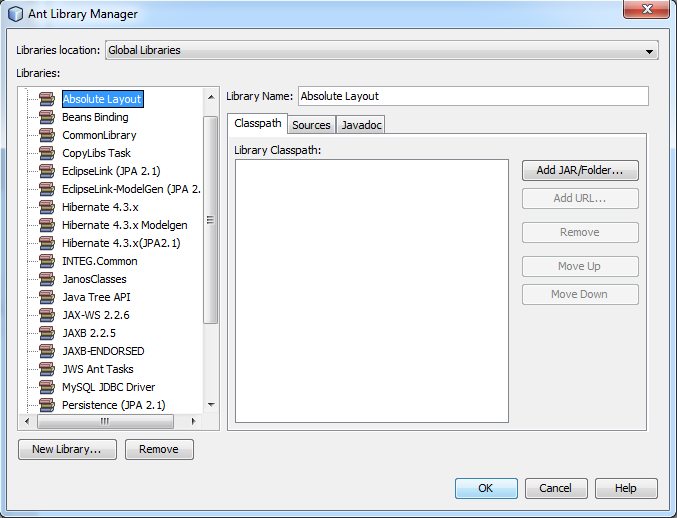
You’ll then want to create two new libraries by selecting the New Library button at the bottom left of the dialog box. This will prompt the New Library Dialog Box which will ask you what you want to name the library and what type it is. When naming, name the library with the _Common.jar file as INTEG.Common and the Janos_Runtime1.8.jar file as JanosLibrary. Once you finish leave the type as it is and click OK. Then you will need to add the _Common.jar file from the SDK file you extracted previously to the library you create which will now be on the left. You can then repeat this process for the Janos_Runtime1.8.jar file.
Adding The Library To A Project
Now that the libraries are created, we’ll want to add them to our project. If you haven’t created a project yet, create a java project to add a library to. Once the project is created, click on File -> Project Properties. This will open the Project Properties Dialog Box of the current project.
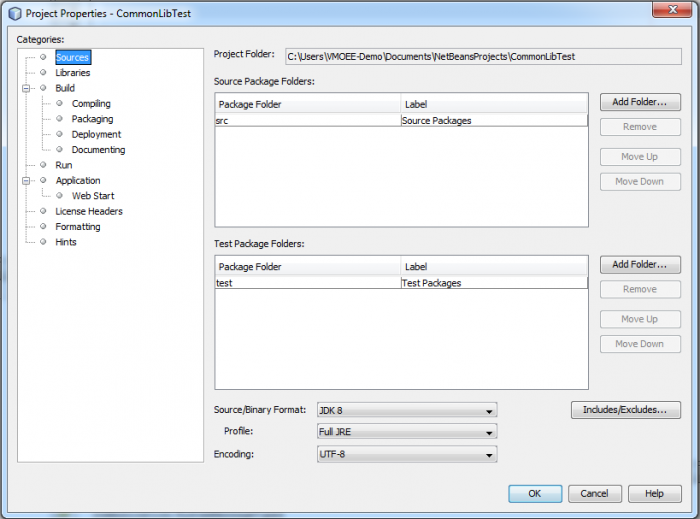
Here we’ll want to click on the Libraries Category and click the Add Library button to add the Janos_Runtime1.8 Library and then the _Common Library we created previously.
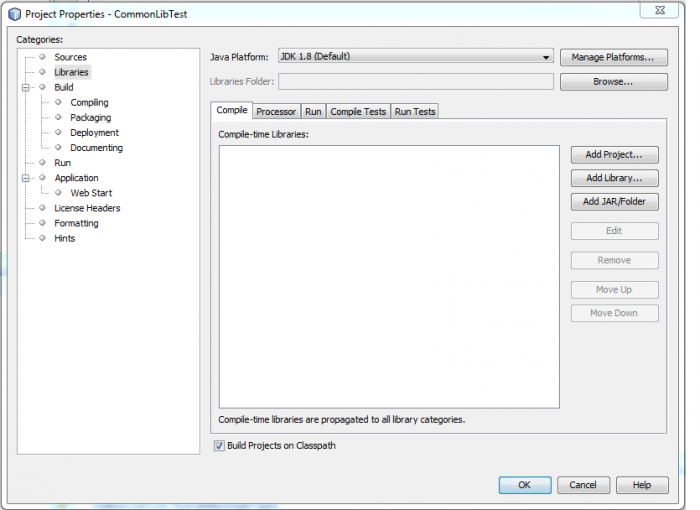
Once the libraries are added, click OK and the project should now include the libraries in them. One thing to note is that the size of the libraries are very big, and including every class in the library might take a lot of space in the JNIOR, so we are going add some code to the xml.build file to only include classes we use from the library in our project. If you want to learn more about editing the xml.build file, click here.
Adding Only The Classes Needed
In NetBeans, go over to the Projects, Services, Files tabs and select the Files tab. Inside the project’s files should be a file called xml.build. Open that file by double clicking it.
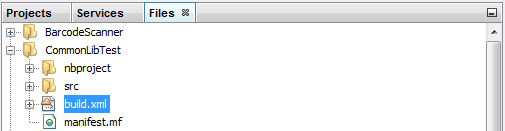
Once the file is open, scroll down to the bottom of the file right before the </project> tag at the files end. The first bit of code we are adding is to set the bootclasspath and reference the correct place the files are in. Take the code below and copy and paste it above the </project> tag. One change you’ll need to make to this code is where there is capitalized text, it needs to be changed to file location of the SDK file that was extracted and mentioned at the beginning of this tutorial.
<target name="-pre-init">
<!-- tell the compiler about our library
-->
<property name="javac.compilerargs" value="-bootclasspath '${libs.JanosClasses.classpath}'" />
<!-- set a property for the INTEG SDK
-->
<property name="janossdk.home" value="INSERT FILE PATH HERE" /> <!-- set a property for the javadepencies application
-->
<property name="janossdk.javadependencies" value="${janossdk.home}/JavaDependencies.exe" />
</target>Here is where this code should be inserted for the libraries to only use classes referenced in the project. Take the code below and copy and paste it below the previous code, but not past the </project> tag.
<target name="-pre-jar">
<!--
before we build the JAR file we need to get all of the classes out of the
library that our application depends on
-->
<echo>Update classes directory with library dependencies</echo>
<exec dir="" resolveexecutable="true"
executable="${janossdk.javadependencies}">
<arg line="${build.classes.dir} '${libs.INTEG.Common.classpath}'" />
</exec>
</target>
Also add the code below so the jar file that you throw into the JNIOR to run it is easier to find. It also updates the current version of the project. Copy and paste this right below the previous code you just added, but not past the </project> tag.
<target name="-post-jar">
<!--
copies the built JAR file out of the dist directory and into the root
of the project folder
-->
<copy file="${dist.jar}" todir="." />
</target>
Now your project should be able to call pre-made classes to help you create the application you want, while not calling every class available and take up space on the JNIOR!